Data 0: README
“The confusion between effectiveness and efficiency that stands between doing the right things and doing things right. There is surely nothing quite so useless as doing with great efficiency what should not be done at all” — Peter F. Drucker (1963)
Digital transformation done right: Unlock better data with cross-organizational dataspaces
To be referenced as: Schlueter Langdon, C. 2025. Digital transformation done right: Unlock better data with cross-organizational dataspaces. Research Note (RN_DCL-Drucker-CGU_2025-02, v2), Drucker Customer Lab, Peter Drucker School of Management, Claremont Graduate University, Claremont, CA
Welcome to the future of digital transformation! Data ecosystems and dataspaces are game-changing infrastructure for secure, trustful cross-organizational data sharing at scale. They fuel digital transformation—not just with ‘Big Data,’ but better data—so you can do the right thing first by obtaining data with relevant and accurate information content. This README is an executive-level introduction, grounded in science, and a guide to deeper resources.
Benefits
Timing is everything: As data fuels digital transformation, new dataspace technology has emerged to provide better, more reliable data. Distributed by design—like the Internet—it is, therefore, inherently more flexible and resilient. Often associated with Web3 (see McKinsey 2023), dataspace infrastructure goes beyond operational efficiency, unlocking opportunities of strategic importance.
Strategically, make your organization more readily adaptive in an era of relentless, rapid disruption—natural disasters, trade upheavals, even wars, and more—by forming ecosystems with more resilient supply chains. Ecosystems have long looked good on paper, but now technology has caught up with the theory. Dataspaces for trusted cross-organizational data sharing serve as a key enabler for actual resource exchange across an ecosystem’s interconnected organizations. See Data 1: Ecosystems 2.0 – Built on Data
Operationally, accelerate to ‘China speed’ and reduce costs—such as by adopting digital twins. Why destroy a physical product to test safety or reliability when a digital replica can do it faster, cheaper, and repeatedly? Until recently, accessing primary data across multiple supply chain tiers for accurate digital twins was a major bottleneck. Now, dataspace technology removes that hurdle. It unlocks two key value levers: (1) data chains and (2) AI-ready data. Firstly, data chains: They provide critical primary Scope 3 supply chain data for various use cases, including tracing quality issues and faulty parts for targeted recalls, as well as reducing CO₂ emissions through Product Carbon Footprint (PCF) tracking. Secondly, “get your company’s data ready for generative AI” (Davenport & Tiwari 2024). To maximize value and amplify your competitive advantage—your “Differentiated GenAI,” so to speak—Large Language Models (LLMs) must be trained on proprietary information and historical business data that reflect how you run your business. This is where Retrieval-Augmented Generation (RAG) comes in, enhancing LLMs by integrating external knowledge retrieval to improve accuracy, relevance, and competitive differentiation while reducing hallucinations. Dataspace technology bridges internal data silos and connects seamlessly with key external business partners to efficiently extract relevant training data—without complex system integrations—while ensuring built-in data governance.
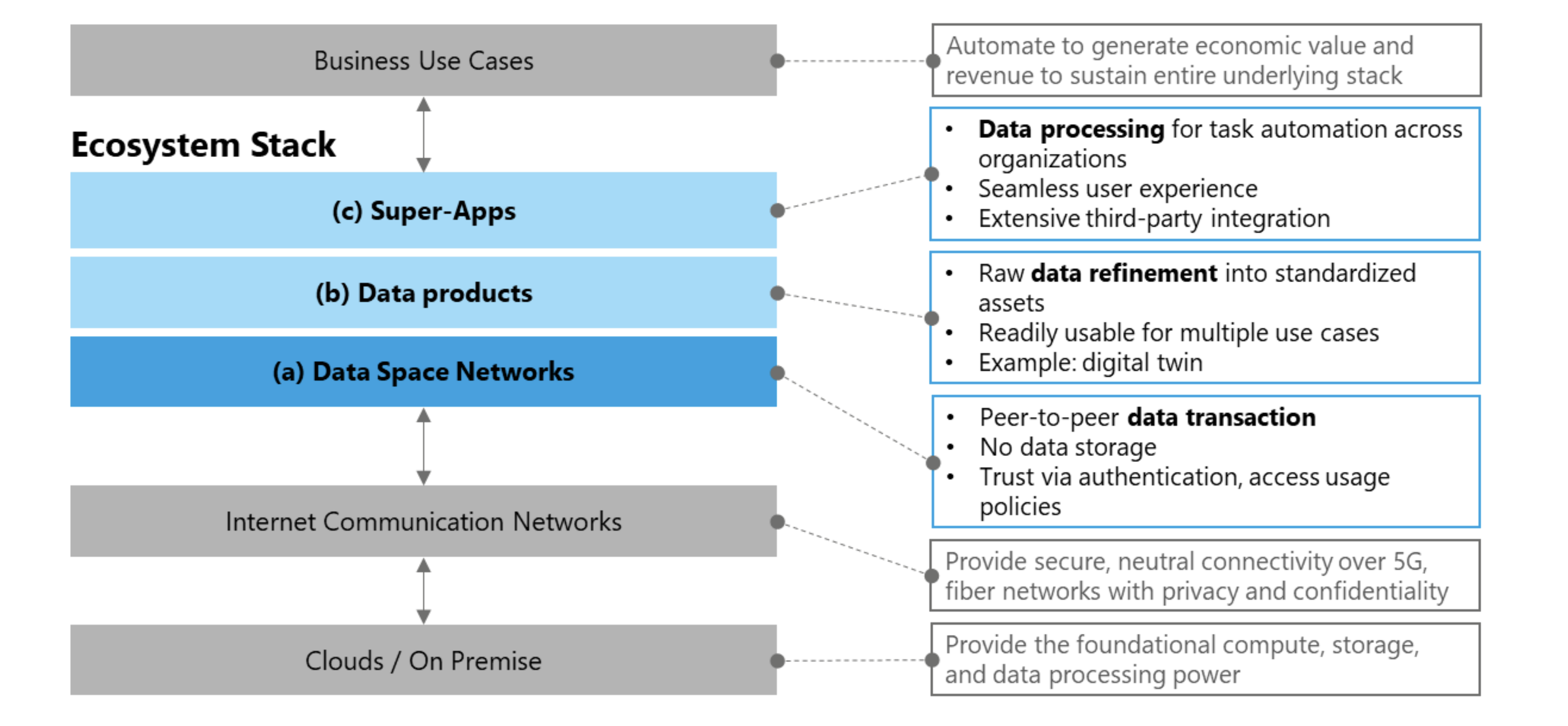
Maturity of data ecosystems: A 3-layer model of the software stack
Data ecosystems may seem complex, but technology has matured to simplify their adoption. Businesses can now seamlessly connect, leverage their capabilities, and stay focused on solving problems for faster results and measurable benefits. Figure 1 illustrates how a data ecosystem seamlessly integrates into your existing IT landscapes by operating atop cloud or on-premises hardware and communication networks to support the automation of your business use case. Drawing on established conceptualizations of information systems (e.g., Turban et al. 2022)—including the abstraction layers of the Open Systems Interconnection (OSI) model, a reference framework by the International Organization for Standardization (ISO/IEC 7498-1:1994)—it has been established how three key layers can be distinguished (Guggenberger et al. 2025; Schlueter Langdon & Schweichhart 2022). The three-layer model of a data ecosystem software stack consists of:
(1) Dataspace network: Peer-to-peer data transactions (see Data 2: Dataspaces 101)
(2) Data products: Raw data refinement (see Data 3: Data products, digital twins)
(3) Super-apps: Data processing across traditional boundaries (see Data 4: Dataspace super-apps)
This model further illustrates that, similar to the Internet, the network layer of the dataspace (dark gray) is industry-agnostic, whereas data products and applications are tailored to specific industries or even individual companies.
Ease of implementation: Software-as-a-Service solutions built on an open-source core
While nothing about this is easy at the code level, first data ecosystems like Catena-X* have emerged with solutions that shield complexity and simplify adoption (see What is Catena-X). Backed by government seed funding—similar to DARPA’s role in developing core Internet technologies—the foundational software is open-source and designed to serve not only global corporations but also small and medium-sized businesses (available in the Tractus-X project of the Eclipse foundation). While DARPA initially envisioned military applications, the push for modern data infrastructure upgrades originated in Europe, driven by its strong focus on data privacy and sovereignty. The European Union’s General Data Protection Regulation (GDPR) has set a global standard for privacy laws, influencing legislation such as California’s CCPA and CPRA. Delivered as a fully managed, browser-based SaaS solution, there’s no need for complex systems integration. Onboarding is as simple as ordering mobile phone service: complete online forms, make a credit card payment, and you’re ready to go. No more tinkering under the hood or soldering wires—just open your browser and start doing the right thing first by ensuring better data for your use cases and AI. Our two case studies provide insights into first best practices and lessons learned:
• Auto 6: Sustainability with Catena-X
• Auto 5: Mobility Super-app Disruption
References
Davenport, T., and P. Tiwari. 2024. Is Your Company’s Data Ready for Generative AI? Harvard Business Review (March), link
Drucker, P. 1963. Managing for Business Effectiveness. Harvard Business Review (May), link
Guggenberger, T. M., C. Schlueter Langdon, and B. Otto. 2025. “Data Spaces as Meta-Organisations. European Journal of Information Systems, January, doi:10.1080/0960085X.2025.2451250: 1–21, link
ISO/IEC 7498-1:1994. Information technology – Open Systems Interconnection – Basic Reference Model: The Basic Model (Ed. 1, 1994; last reviewed and confirmed in 2000), link
McKinsey. 2023. What is Web3. Explainers (2023-10-10), McKinsey & Company, New York City, New York, link
Mertens C. 2025. Establishing a Unified, Sovereign, and Open Digital Infrastructure: A Vision for Telecommunication Providers. Position Paper (March), International Data Spaces Association (IDSA), Dortmund, link
Schlueter Langdon, C., and K. Schweichhart. 2022. Dataspaces: First Applications in Mobility and Industry. In: Otto, B. et al. (eds.). Dataspaces – Part IV Solutions & Applications. Springer Nature, Switzerland: 493-511, link
Telekom DIH. 2024. RoX: Habeck kickoff, lauch@Duerr. Insights story (2024-12-05), T-Systems International, Frankfurt, link
Turban, E., L. Volonino, G. R. Wood, R. D. Watson. 2022. Information technology for management. Wiley 12th ed. Hoboken, NJ
* The Catena-X Consortium served as the tech incubator for today’s Catena-X data ecosystem, a $250 million, 3-year (2021–2024) initiative with automotive use cases, uniting 28 partners, including BMW, Mercedes-Benz, Volkswagen, and tier-1s from Bosch to ZF, and software vendors like SAP. This author wrote Deutsche Telekom into it from the initial 15-page government proposal to finalizing the 1,700-page agreement while serving on the 3-member agile SAFe-based Product Management team responsible for creating and delivering the software release, now available as an open-source reference implementation in the Eclipse Foundation’s Tractus-X project. As a scientist-manager, the author is grateful for successfully transfering research innovation into industrial applications through close collaboration with leading scientists such as Boris Otto (Fraunhofer), often regarded as a key academic pioneer of dataspaces, and Frank Koester (DLR).
Share